Tiếp theo phần 1 đề cập tới cách tiếp cận Lakehouse, các phần sau này sẽ giới thiệu một kiến trúc tham chiếu sử dụng các dịch vụ AWS để tạo từng layer được mô tả trong kiến trúc Lakehouse. Phần 2 đã đi sâu về Ingestion Layer và Storage Layer, phần 3 sẽ làm rõ 2 layer quan trọng còn lại, hoàn thiện tổng quan về Kiến trúc Tham chiếu Lakehouse.
Xem thêm phần 1 về Cách tiếp cận Lakehouse.
Xem thêm phần 2 về Ingestion Layer và Storage Layer
3. Data Processing Layer
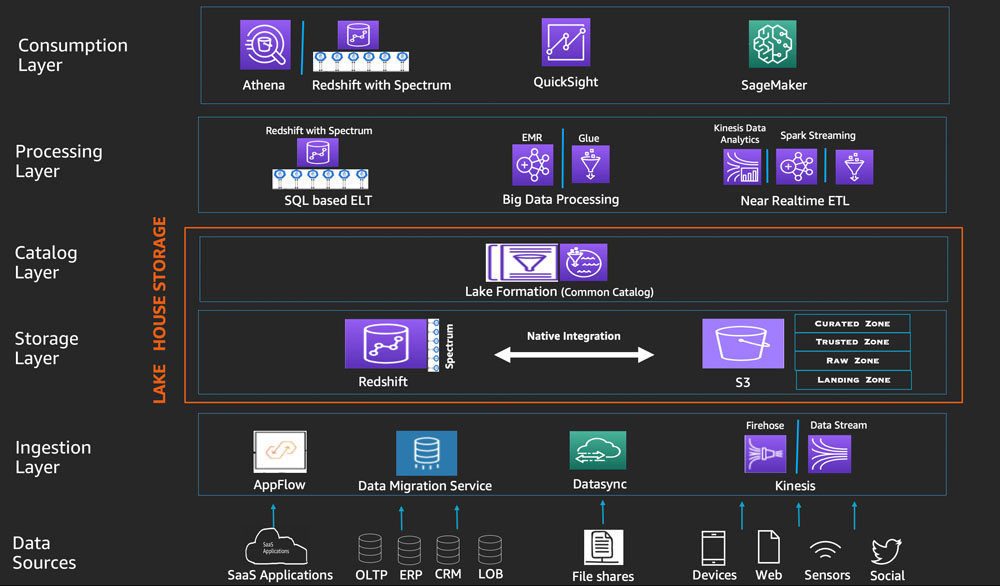
Processing layer của Kiến trúc Lakehouse cung cấp nhiều thành phần được xây dựng có mục đích cho phép nhiều trường hợp sử dụng và xử lý dữ liệu khác nhau, phù hợp với cấu trúc duy nhất (dạng bảng phẳng, phân cấp hoặc không có cấu trúc) và tốc độ (hàng loạt hoặc phát trực tuyến) của tập dữ liệu trong Lakehouse. Mỗi thành phần có thể đọc và ghi dữ liệu vào cả Amazon S3 và Amazon Redshift (gọi chung là bộ lưu trữ Lakehouse).
Chúng ta có thể sử dụng các thành phần của lớp xử lý để xây dựng các công việc xử lý dữ liệu có thể đọc và ghi dữ liệu được lưu trữ trong cả data warehouse và lưu trữ data lake bằng cách sử dụng các giao diện sau:
-
Amazon Redshift SQL (với Redshift Spectrum)
-
Apache Spark jobs running Amazon EMR.
-
Apache Spark jobs running on AWS Glue
Bạn có thể thêm metadata từ các dataset kết quả vào danh mục Lake Formation trung tâm bằng cách sử dụng trình thu thập dữ liệu AWS Glue hoặc API của Lake Formation.
Bạn có thể sử dụng các thành phần được xây dựng có mục đích để xây dựng các pipeline chuyển đổi dữ liệu:
-
SQL-based ELT using Amazon Redshift (with Redshift Spectrum)
-
Big data processing using AWS Glue or Amazon EMR
-
Near-real-time streaming data processing using Amazon Kinesis
-
Near-real-time streaming data processing using Spark Streaming on AWS Glue
-
Near-real-time streaming data processing using Spark Streaming on Amazon EMR
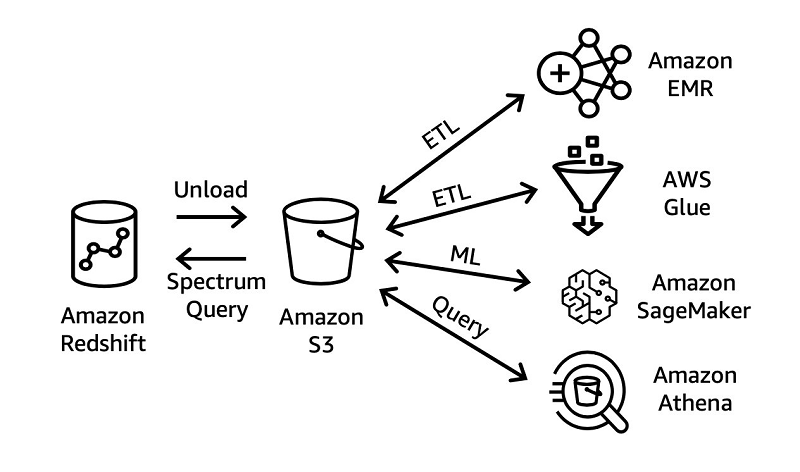
3.1. SQL based ELT
Để chuyển đổi dữ liệu có cấu trúc trong storage layer Lakehouse, bạn có thể xây dựng các pipeline ELT mạnh mẽ bằng cách sử dụng ngữ nghĩa SQL quen thuộc. Các pipeline ELT này có thể sử dụng khả năng xử lý song song hàng loạt (MPP) trong Amazon Redshift và khả năng trong Redshift Spectrum để tạo ra hàng nghìn node tạm thời để mở rộng quy mô xử lý đến petabyte dữ liệu. Các pipeline ELT dựa trên quy trình được lưu trữ tương tự trên Amazon Redshift có thể biến đổi những điều sau:
-
Flat structured data được AWS DMS hoặc Amazon AppFlow phân phối trực tiếp vào các staging tables của Amazon Redshift
-
Dữ liệu được lưu trữ trong data lake sử dụng các định dạng tệp nguồn mở như JSON, Avro, Parquet và ORC
Đối với các bước data enrichment, các pipeline này có thể bao gồm các câu lệnh SQL nối các internal dimension tables với các large fact tables được lưu trữ trong data lake S3 (sử dụng lớp Redshift Spectrum). Bước cuối cùng, các pipeline xử lý dữ liệu có thể chèn curated, enriched, và modeled data vào internal table của Amazon Redshift hoặc external table được lưu trữ trong Amazon S3.
3.2. Big data processing
Để xử lý tích hợp khối lượng lớn dữ liệu bán cấu trúc, phi cấu trúc hoặc có cấu trúc cao được lưu trữ trên storage layer Lakehouse (Amazon S3 và Amazon Redshift), bạn có thể xây dựng các công việc xử lý big data bằng Apache Spark và chạy chúng trên AWS Glue hoặc Amazon EMR. Những công việc này có thể sử dụng các trình kết nối nguồn mở cũng như Spark native để truy cập và kết hợp relational data được lưu trữ trong Amazon Redshift với complex flat hoặc hierarchical structured data được lưu trữ trong Amazon S3. Những công việc tương tự này có thể lưu trữ các tập dữ liệu đã xử lý trở lại data lake S3, data warehouse Amazon Redshift hoặc cả hai trong storage layer Lakehouse.
AWS Glue cung cấp ETL serverless, pay-per-use, cho mỗi lần sử dụng để cho phép các pipeline ETL có thể xử lý hàng chục terabyte dữ liệu, mà không cần phải quản lý các servers hoặc clusters. Để tăng tốc độ phát triển ETL, AWS Glue tự động tạo mã ETL và cung cấp các cấu trúc dữ liệu thường được sử dụng cũng như ETL transformation (để validate, clean, transform, và flatten data). AWS Glue cung cấp khả năng tích hợp để xử lý dữ liệu được lưu trữ trong Amazon Redshift cũng như S3 data lake.
Trong cùng một công việc, AWS Glue có thể tải và xử lý dữ liệu Amazon Redshift được lưu trữ bằng định dạng flat table cũng như các tập dữ liệu được lưu trữ trên data lake S3 được lưu trữ bằng các định dạng nguồn mở phổ biến như CSV, JSON, Parquet và Avro. Các công việc AWS Glue ETL có thể tham chiếu cả các bảng được lưu trữ trên Amazon Redshift và Amazon S3 bằng cách truy cập chúng thông qua danh mục Lake Formation chung (mà trình thu thập dữ liệu AWS Glue điền vào bằng cách thu thập dữ liệu của Amazon S3 cũng như Amazon Redshift). AWS Glue ETL cung cấp khả năng xử lý từng bước partitioned data. Ngoài ra, AWS Glue cung cấp các triggers và workflow capabilities mà bạn có thể sử dụng để xây dựng pipeline xử lý dữ liệu đầu cuối nhiều bước bao gồm các job dependencies cũng như chạy các parallel steps.
Bạn có thể tự động chia tỷ lệ các cụm EMR để đáp ứng các nhu cầu tài nguyên khác nhau của các pipeline xử lý dữ liệu lớn có thể xử lý lên đến petabyte dữ liệu. Các pipeline này có thể sử dụng các nhóm Phiên bản Spot Amazon Elastic Compute Cloud (Amazon EC2) khác nhau để mở rộng quy mô theo cách tối ưu chi phí.
Các pipeline xử lý dữ liệu Spark based trên Amazon EMR có thể sử dụng như sau:
-
Trình đọc viết tích hợp của Spark để xử lý các tập dữ liệu được lưu trữ trong data lake ở nhiều định dạng nguồn mở khác nhau
-
Đầu nối Spark-Amazon Redshift mã nguồn mở để trực tiếp đọc và ghi dữ liệu trong data warehouse Amazon Redshift
Để đọc schema của các dataset có cấu trúc phức tạp được lưu trữ trên data lake, các Spark ETL trên Amazon EMR job có thể kết nối với danh mục Lake Formation. Điều này được thiết lập với khả năng tương thích AWS Glue và các AWS Identity and Access Management (IAM) policy được thiết lập để cấp phép riêng biệt quyền truy cập vào các bảng AWS Glue và các đối tượng S3 bên dưới.
Các Spark job tương tự có thể sử dụng trình kết nối Spark-Amazon Redshift để đọc cả dữ liệu và schema của dataset được lưu trữ trên Amazon Redshift. Bạn có thể sử dụng Spark và Apache Hudi để xây dựng pipeline xử lý dữ liệu gia tăng hiệu suất cao Amazon EMR.
3.3. Near-real-time ETL
Để kích hoạt một số use case sử dụng modern analytics, bạn cần thực hiện các hành động sau, tất cả trong near-real time:
-
Nhập khối lượng lớn high-frequency hoặc streaming data
-
Validate, clean, và enrich
-
Chuẩn bị sẵn sàng để tiêu thụ trong kho lưu trữ của Lakehouse
Bạn có thể xây dựng các pipeline dẫn có thể dễ dàng mở rộng quy mô để xử lý khối lượng lớn dữ liệu trong thời gian gần thực bằng cách sử dụng một trong các cách sau:
-
Amazon Kinesis Data Analytics for SQL/Flink
-
Spark streaming on either AWS Glue or Amazon EMR
-
Kinesis Data Firehose integrated with AWS Lambda
Kinesis Data Analytics, AWS Glue và Kinesis Data Firehose cho phép bạn xây dựng near-real-time data processing pipelines mà không cần phải tạo hoặc quản lý cơ sở hạ tầng máy tính. Các pipeline Kinesis Data Firehose và Kinesis Data Analytics mở rộng quy mô linh hoạt để phù hợp với thông lượng của nguồn, trong khi các công việc phát trực tuyến Spark dựa trên Amazon EMR và AWS Glue có thể được thu nhỏ trong vài phút bằng cách chỉ định các thông số tỷ lệ.
Kinesis Data Analytics cho các Flink/SQL based streaming pipelines thường đọc các bản ghi từ Amazon Kinesis Data Streams (trong ingestion layer của Kiến trúc Lakehouse), áp dụng các phép biến đổi và ghi dữ liệu đã xử lý vào Kinesis Data Firehose. Spark streaming pipelines thường đọc các bản ghi từ Kinesis Data Streams (trong ingestion layer của Kiến trúc Lakehouse), áp dụng các phép biến đổi cho chúng và ghi dữ liệu đã xử lý vào một Kinesis data stream khác, được liên kết với Kinesis Data Firehose delivery stream.
Luồng Firehose delivery stream có thể phân phối dữ liệu đã xử lý tới Amazon S3 hoặc Amazon Redshift trong storage layer Lakehouse. Để xây dựng các near-real-time pipelines đơn giản hơn yêu cầu các simple, stateless transformations, bạn có thể nhập dữ liệu trực tiếp vào Kinesis Data Firehose và chuyển đổi các micro-batches các incoming records bằng cách sử dụng hàm Lambda được Kinesis Data Firehose invoke. Kinesis Data Firehose cung cấp các micro-batches records đã được biến đổi tới Amazon S3 hoặc Amazon Redshift trong storage layer Lakehouse.
Với khả năng cung cấp dữ liệu tới Amazon S3 cũng như Amazon Redshift, Kinesis Data Firehose cung cấp giao diện bộ lưu trữ Lakehouse thống nhất cho near-real-time ETL pipelines trong processing layer. Trên Amazon S3, Kinesis Data Firehose có thể lưu trữ dữ liệu trong các tệp Parquet hoặc ORC hiệu quả được nén bằng codec mã nguồn mở như ZIP, GZIP và Snappy.
4. Data Consumption Layer
Kiến trúc tham chiếu Lakehouse của chúng tôi dân chủ hóa việc tiêu thụ dữ liệu trên các persona types khác nhau bằng cách cung cấp các dịch vụ AWS được xây dựng với mục đích cho phép nhiều trường hợp sử dụng phân tích khác nhau, chẳng hạn như interactive SQL queries, BI và ML. Các dịch vụ này sử dụng giao diện Lakehouse thống nhất để truy cập tất cả dữ liệu và metadata được lưu trữ trên Amazon S3, Amazon Redshift và danh mục Lake Formation. Chúng có thể sử dụng flat relational data được lưu trữ trong các bảng Amazon Redshift cũng như dữ liệu có cấu trúc hoặc không có cấu trúc phẳng hoặc phức tạp được lưu trữ trong các đối tượng S3 sử dụng các định dạng tệp mở như JSON, Avro, Parquet và ORC.
4.1. Interactive SQL
Để khám phá tất cả dữ liệu được lưu trữ trong bộ lưu trữ Lakehouse bằng cách sử dụng interactive SQL, các nhà phân tích kinh doanh và nhà khoa học dữ liệu có thể sử dụng Amazon Redshift (với Redshift Spectrum) hoặc Athena. Bạn có thể chạy các truy vấn SQL kết hợp flat, relational, structured dimensions data được lưu trữ trong một Amazon Redshift cluster, với hàng terabyte flat hoặc complex structured historical facts data trong Amazon S3, được lưu trữ bằng các định dạng tệp mở như JSON, Avro, Parquet, và ORC.
Khi truy vấn tập dữ liệu trong Amazon S3, cả Athena và Redshift Spectrum đều tìm nạp schema được lưu trữ trong danh mục Lake Formation và áp dụng nó khi đọc (schema-on-read). Bạn có thể chạy các truy vấn Athena hoặc Amazon Redshift trên bảng điều khiển tương ứng của chúng hoặc có thể gửi chúng tới các điểm cuối JDBC hoặc ODBC.
Athena có thể chạy ANSI SQL phức tạp trên hàng chục terabyte dữ liệu được lưu trữ trong Amazon S3 mà không yêu cầu bạn phải tải nó vào cơ sở dữ liệu trước. Athena không có máy chủ, vì vậy không có cơ sở hạ tầng để thiết lập hoặc quản lý và bạn chỉ phải trả cho lượng dữ liệu được quét bởi các truy vấn bạn chạy. Khả năng truy vấn liên kết trong Athena cho phép các truy vấn SQL có thể kết hợp dữ liệu thực tế được lưu trữ trong Amazon S3 với các dimension table được lưu trữ trong một cụm Amazon Redshift mà không cần phải di chuyển dữ liệu theo một trong hai hướng.
Bạn cũng có thể bao gồm dữ liệu trực tiếp trong cơ sở dữ liệu hoạt động trong cùng một câu lệnh SQL bằng cách sử dụng các truy vấn liên kết Athena. Athena cung cấp kết quả nhanh hơn và chi phí thấp hơn bằng cách giảm lượng dữ liệu mà nó quét bằng cách tận dụng thông tin phân vùng tập dữ liệu được lưu trữ trong danh mục Lake Formation. Bạn có thể giảm chi phí hơn nữa bằng cách lưu trữ kết quả của một truy vấn lặp lại bằng cách sử dụng các câu lệnh Athena CTAS.
Amazon Redshift cung cấp khả năng SQL mạnh mẽ được thiết kế để xử lý phân tích trực tuyến nhanh chóng (OLAP) của các tập dữ liệu rất lớn được lưu trữ trong bộ lưu trữ Lakehouse (trên toàn bộ cụm Amazon Redshift MPP cũng như data lake S3). Trình tối ưu hóa truy vấn mạnh mẽ trong Amazon Redshift có thể nhận các truy vấn phức tạp của người dùng được viết bằng cú pháp giống PostgreSQL và tạo các kế hoạch truy vấn hiệu suất cao chạy trên cụm Amazon Redshift MPP cũng như nhóm các node Redshift Spectrum (để truy vấn dữ liệu trong Amazon S3) .
Amazon Redshift cung cấp results caching capabilities để giảm thời gian chạy truy vấn cho các lần chạy lặp lại cùng một truy vấn theo thứ tự cường độ. Với các chế độ xem cụ thể hóa trong Amazon Redshift, bạn có thể tính toán trước các phép nối phức tạp một lần (và dần dần làm mới chúng) để đơn giản hóa đáng kể và tăng tốc các truy vấn xuôi dòng mà người dùng cần viết. Amazon Redshift cung cấp tính năng mở rộng quy mô đồng thời, giúp tăng các cluster tạm thời bổ sung trong vòng vài giây, để hỗ trợ số lượng truy vấn đồng thời gần như không giới hạn. Bạn có thể ghi kết quả truy vấn của mình trở lại bảng gốc của Amazon Redshift hoặc vào các bảng bên ngoài được lưu trữ trên data lake S3 (sử dụng Redshift Spectrum).
4.2. Machine learning
Thông thường, Data scientists cần khám phá, tìm hiểu và xây dựng tính năng cho nhiều loại dataset có cấu trúc và phi cấu trúc để chuẩn bị cho việc đào tạo các mô hình ML. Giao diện Lakehouse (giao diện SQL tương tác sử dụng Amazon Redshift với giao diện Athena và Spark) đơn giản hóa và đẩy nhanh các bước chuẩn bị dữ liệu này bằng cách cung cấp cho các Data scientists những điều sau:
-
Danh mục Lake Formation hợp nhất để tìm kiếm và khám phá tất cả dữ liệu được lưu trữ trong bộ nhớ Lakehouse
-
Khả năng tương tác SQL dựa trên Amazon Redshift SQL và Athena để truy cập, khám phá và chuyển đổi tất cả dữ liệu trong bộ lưu trữ Lakehouse
-
Quyền truy cập dựa trên Spark hợp nhất để bao bọc và chuyển đổi tất cả các tập dữ liệu được lưu trữ trên bộ nhớ lưu trữ của Lakehouse (có cấu trúc cũng như không có cấu trúc) và biến chúng thành các tập hợp tính năng
Sau đó, các nhà khoa học dữ liệu phát triển, đào tạo và triển khai các mô hình ML bằng cách kết nối Amazon SageMaker với lớp lưu trữ Lakehouse và truy cập các bộ tính năng đào tạo.
SageMaker là một dịch vụ được quản lý hoàn toàn, cung cấp các thành phần để xây dựng, đào tạo và triển khai các mô hình ML bằng cách sử dụng môi trường phát triển tương tác (IDE) được gọi là SageMaker Studio. Trong Studio, bạn có thể tải lên dữ liệu, tạo sổ ghi chép mới, đào tạo và điều chỉnh mô hình, di chuyển qua lại giữa các bước để điều chỉnh thử nghiệm, so sánh kết quả và triển khai mô hình để sản xuất tất cả ở một nơi bằng giao diện trực quan thống nhất.
SageMaker cũng cung cấp Jupyter notebooks mà bạn có thể xoay vòng bằng một vài cú nhấp chuột. SageMaker notebooks cung cấp tài nguyên máy tính linh hoạt, tích hợp git, chia sẻ dễ dàng, thuật toán ML được định cấu hình trước, hàng chục ví dụ ML sẵn có và tích hợp AWS Marketplace cho phép dễ dàng triển khai hàng trăm thuật toán được đào tạo trước. Máy tính xách tay SageMaker được cấu hình sẵn với tất cả deep learning frameworks chính bao gồm TensorFlow, PyTorch, Apache MXNet, Chainer, Keras, Gluon, Horovod, Scikit-learning và Deep Graph Library.
Các mô hình ML được đào tạo về các managed compute instances bởi SageMaker, bao gồm cả EC2 Spot Instances hiệu quả cao về chi phí. Bạn có thể tổ chức nhiều công việc đào tạo bằng cách sử dụng SageMaker Experiments. Bạn có thể xây dựng các công việc đào tạo bằng cách sử dụng các thuật toán tích hợp sẵn của SageMaker, thuật toán tùy chỉnh của bạn hoặc hàng trăm thuật toán mà bạn có thể triển khai từ AWS Marketplace. SageMaker Debugger cung cấp khả năng hiển thị đầy đủ về các công việc đào tạo mô hình. SageMaker cũng cung cấp tính năng automatic hyperparameter tuning cho các công việc đào tạo ML.
Bạn có thể triển khai các SageMaker trained models vào sản xuất với một vài cú nhấp chuột và dễ dàng mở rộng quy mô chúng trên một nhóm fully managed EC2 instances. Bạn có thể chọn từ nhiều loại EC2 instance và đính kèm GPU-powered inference acceleration. Sau khi bạn triển khai các mô hình, SageMaker có thể theo dõi các chỉ số chính của mô hình để có độ chính xác trong suy luận và phát hiện bất kỳ sai lệch khái niệm nào.
4.3. Business intelligence
Amazon QuickSight cung cấp khả năng không cần máy chủ để dễ dàng tạo và xuất bản các bảng điều khiển BI tương tác phong phú. Các nhà phân tích kinh doanh có thể sử dụng giao diện SQL tương tác Athena hoặc Amazon Redshift để cấp nguồn cho bảng điều khiển QuickSight với dữ liệu trong bộ nhớ Lakehouse. Ngoài ra, bạn có thể tạo nguồn dữ liệu bằng cách kết nối QuickSight trực tiếp với cơ sở dữ liệu hoạt động như MS SQL, Postgres và các ứng dụng SaaS như Salesforce, Square và ServiceNow. Để đạt được hiệu suất cực nhanh cho trang tổng quan, QuickSight cung cấp một công cụ tính toán và lưu vào bộ nhớ đệm trong bộ nhớ được gọi là SPICE. SPICE tự động sao chép dữ liệu để có tính khả dụng cao và cho phép hàng nghìn người dùng đồng thời thực hiện phân tích nhanh, tương tác trong khi bảo vệ cơ sở hạ tầng dữ liệu cơ bản của bạn.
QuickSight làm phong phú thêm các trang tổng quan và hình ảnh với thông tin chi tiết ML độc đáo, được tạo tự động, chẳng hạn như dự báo, phát hiện bất thường và điểm nổi bật tường thuật. QuickSight tích hợp nguyên bản với SageMaker để cho phép bổ sung thông tin chi tiết dựa trên mô hình ML tùy chỉnh bổ sung vào bảng điều khiển BI của bạn. Bạn có thể truy cập trang tổng quan QuickSight từ bất kỳ thiết bị nào bằng ứng dụng QuickSight hoặc nhúng trang tổng quan vào các ứng dụng web, cổng thông tin và trang web. QuickSight tự động mở rộng quy mô đến hàng chục nghìn người dùng và cung cấp cost-effective pay-per-session pricing model.
Cùng nhìn lại mô hình tổng thể tham khảo từ giải pháp của AWS do VTI Cloud tổng hợp
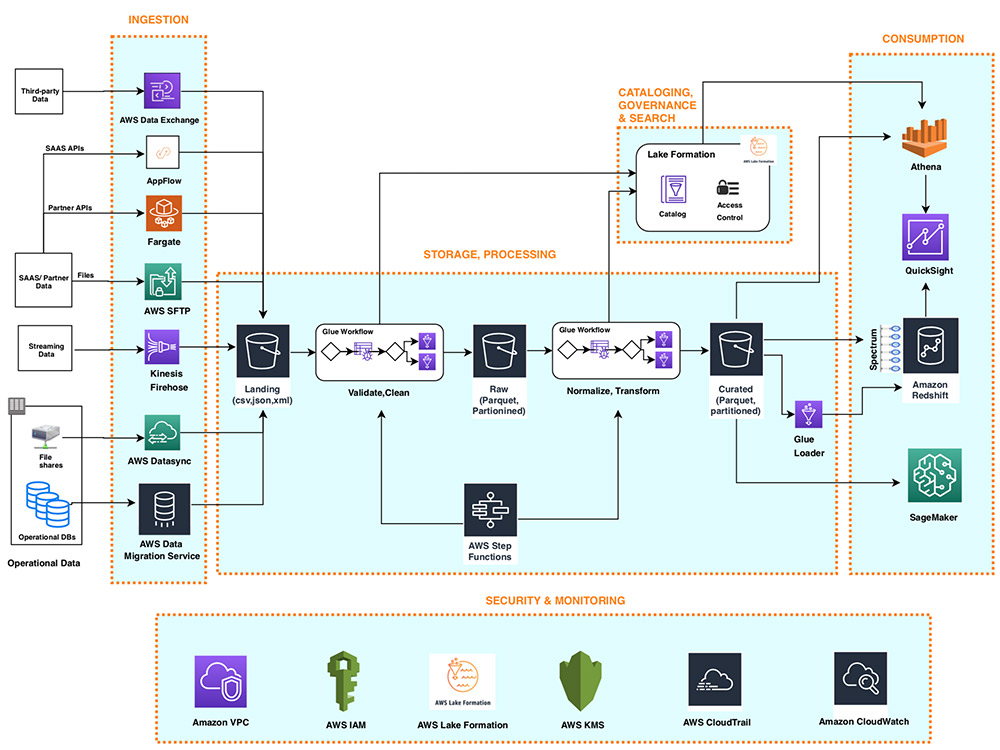
Tóm tắt chuỗi bài viết về Data Lakehouse với AWS
Kiến trúc Lakehouse, được xây dựng dựa trên danh mục các dịch vụ được xây dựng có mục đích, sẽ giúp bạn nhanh chóng nhận được thông tin chi tiết từ tất cả dữ liệu cho tất cả người dùng và sẽ cho phép bạn xây dựng cho tương lai để có thể dễ dàng thêm các phương pháp và công nghệ phân tích mới khi chúng trở nên khả dụng.
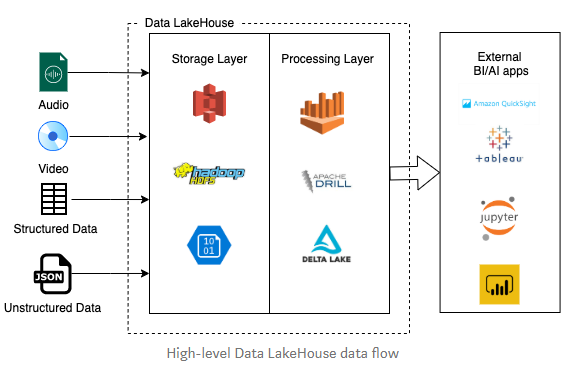
Trong bài đăng này, chúng tôi đã mô tả một số dịch vụ AWS được xây dựng theo mục đích mà bạn có thể sử dụng để tạo năm layer của Kiến trúc Lakehouse. Chúng tôi đã giới thiệu nhiều tùy chọn để thể hiện tính linh hoạt và khả năng phong phú được cung cấp bởi dịch vụ AWS phù hợp cho nhiều nhu cầu công việc của bạn.
Về VTI Cloud
VTI Cloud là Đối tác cấp cao (Advanced Consulting Partner) của AWS, với đội ngũ hơn 50+ kỹ sư về giải pháp được chứng nhận bởi AWS. Với mong muốn hỗ trợ khách hàng trong hành trình chuyển đổi số và dịch chuyển lên đám mây AWS, VTI Cloud tự hào là đơn vị tiên phong trong việc tư vấn giải pháp, phát triển phần mềm và triển khai hạ tầng AWS cho khách hàng tại Việt Nam và Nhật Bản.
Xây dựng các kiến trúc an toàn, linh hoạt, hiệu suất cao, và tối ưu chi phí cho khách hàng là nhiệm vụ hàng đầu của VTI Cloud trong sứ mệnh công nghệ hóa doanh nghiệp.