4. Design Goals
Trong các phần trước, tôi đã mô tả chi tiết kiến trúc đám mây và các thành phần của nó để hỗ trợ hoạt động kinh doanh phát trực tuyến video (video streaming) của Netflix. Trong phần này và các phần tiếp theo, tôi sẽ đi sâu hơn vào phân tích kiến trúc thiết kế này. Tôi sẽ bắt đầu với danh sách các mục tiêu thiết kế quan trọng nhất như sau:
- Đảm bảo tính khả dụng cao cho các dịch vụ phát trực tuyến ở quy mô toàn cầu.
- Khắc phục sự cố mạng và sự cố hệ thống bằng khả năng phục hồi.
- Giảm thiểu độ trễ phát trực tuyến cho mọi thiết bị được hỗ trợ trong các điều kiện mạng khác nhau.
- Hỗ trợ khả năng mở rộng theo khối lượng yêu cầu cao.
Trong các phần phụ, tôi sẽ phân tích tính khả dụng của dịch vụ streaming và độ trễ tối ưu tương ứng của nó. Trong phần 6, chúng ta xem xét và phân tích sâu hơn về các cơ chế phục hồi như Chaos Engineering trong khi phần 7 sẽ đề cập đến khả năng mở rộng của các dịch vụ streaming.
4.1 Tính khả dụng cao
Theo định nghĩa, tính khả dụng của một hệ thống được đo lường dựa trên số lần phản hồi được đáp ứng cho một yêu cầu trong một khoảng thời gian, mà không đảm bảo rằng nó chứa phiên bản thông tin mới nhất. Trong thiết kế hệ thống của chúng tôi, tính khả dụng của các dịch vụ streaming phụ thuộc vào cả tính khả dụng của các dịch vụ Backend và máy chủ OCAs lưu giữ các tệp streaming video.
Mục tiêu của các dịch vụ Backend là có được danh sách các OCA mạnh nhất ở gần một máy khách cụ thể, từ bộ nhớ cache hoặc bằng cách thực thi một số microservices. Do đó, tính khả dụng của nó phụ thuộc vào các thành phần khác nhau liên quan đến yêu cầu Phát lại (Playback request): bộ cân bằng tải (AWS ELB), máy chủ proxy (Dịch vụ cổng API), API Play, thực thi microservices, kho lưu trữ bộ nhớ đệm (EVCache) và kho dữ liệu (Cassandra):
- Bộ cân bằng tải có thể cải thiện tính khả dụng bằng cách định tuyến lưu lượng truy cập đến các máy chủ proxy khác nhau để ngăn quá tải khối lượng công việc.
- Play API kiểm soát việc thực thi các microservices với thời gian chờ thông qua các lệnh Hystrix có thể giúp ngăn chặn các cascading failures đối với các dịch vụ khác.
- Microservices có thể phản hồi Play AI với dữ liệu trong bộ nhớ đệm trong trường hợp cuộc gọi đến các dịch vụ bên ngoài hoặc kho dữ liệu mất nhiều thời gian hơn dự kiến.
- Bộ nhớ đệm được sao chép để truy cập nhanh hơn.
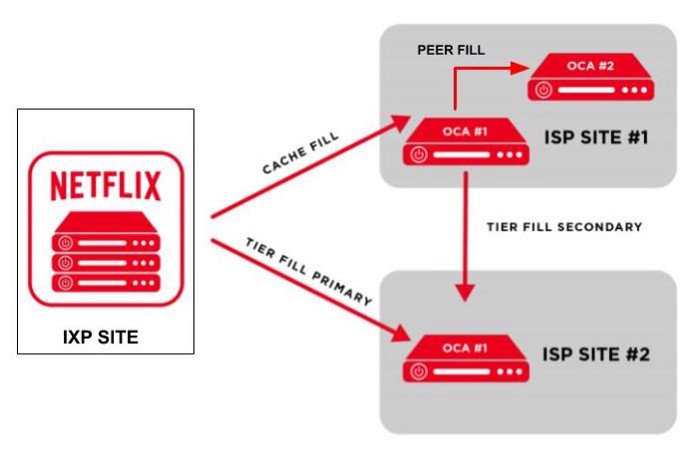
Khi nhận được danh sách các máy chủ OCA từ Backend, khách hàng sẽ thăm dò mạng tới các OCA này và chọn các OCA tốt nhất để kết nối. Nếu OCA đó bị quá tải hoặc không thành công trong quá trình streaming thì khách hàng sẽ chuyển sang một OCA khác tốt hơn hoặc SDK nền tảng sẽ yêu cầu các OCA khác. Do đó, tính khả dụng của nó có mối tương quan cao với tính khả dụng của tất cả các OCA có sẵn trong các ISP hoặc IXP của nó.
Tính khả dụng cao của các dịch vụ streaming trên Netflix đi kèm với chi phí của các hoạt động và dịch vụ AWS đa vùng phức tạp cũng như sự dự phòng của các máy chủ OCAs.
4.2 Độ trễ thấp
Độ trễ của các dịch vụ streaming chủ yếu phụ thuộc vào tốc độ của Play API có thể giải quyết danh sách các OCA tốt như thế nào và mức độ kết nối của máy khách với máy chủ OCA đã chọn.
Như tôi đã mô tả trong phần thành phần API của ứng dụng, Play API không đợi thực thi một microservice mãi mãi vì nó sử dụng các lệnh Hystrix để kiểm soát thời gian chờ kết quả trước khi nhận được dữ liệu không cập nhật từ bộ nhớ cache. Làm như vậy có thể kiểm soát độ trễ có thể chấp nhận được cũng như ngăn chặn cascading failures đối với các dịch vụ khác.
Khách hàng sẽ ngay lập tức chuyển sang các máy chủ OCAs lân cận khác có kết nối mạng đáng tin cậy nhất nếu xảy ra lỗi mạng đối với máy chủ OCA đã chọn đang dùng hoặc máy chủ đó bị quá tải. Nó cũng có thể giảm chất lượng video để phù hợp với chất lượng mạng trong trường hợp phát hiện kết nối mạng bị yếu.
5. Tradeoffs
Trong thiết kế hệ thống được mô tả ở trên, có hai điểm tradeoffs nổi bật đã được thực hiện cẩn thận:
- Độ trễ thấp so với tính nhất quán
- Tính khả dụng cao so với tính nhất quán
Sự cân bằng giữa độ trễ so với tính nhất quán được xây dựng trong thiết kế kiến trúc của các dịch vụ Backend. Play API có thể lấy dữ liệu cũ từ các kho lưu trữ EVCache hoặc từ các kho lưu trữ dữ liệu nhất quán như Cassandra.
Tương tự, cân bằng tính khả dụng trên tính nhất quán sẽ hướng đến việc xây dựng các phản hồi trong độ trễ có thể chấp nhận được mà không yêu cầu thực thi các dịch vụ microservices trên dữ liệu mới nhất trong các kho dữ liệu như Cassandra.
Ngoài ra còn có một sự “đánh đổi” không hoàn toàn phù hợp giữa Khả năng mở rộng và Hiệu suất. Trong sự đánh đổi này, việc cải thiện khả năng mở rộng bằng cách tăng số lượng instances để xử lý nhiều khối lượng công việc hơn có thể khiến hệ thống chạy với hiệu suất ngày càng tăng như mong đợi. Đây có thể là một vấn đề với những kiến trúc thiết kế trong đó khối lượng công việc không được cân bằng hiệu quả giữa các công nhân có sẵn. Tuy nhiên, Netflix đã giải quyết sự đánh đổi này bằng tính năng tự động mở rộng AWS. Chúng tôi sẽ trở lại giải quyết vấn đề này một cách chi tiết hơn trong Phần 7.
6. Khả năng phục hồi (Resilience)
Thiết kế một hệ thống cloud có khả năng tự phục hồi sau các thất bại hay outages đã luôn là một trong những mục tiêu dài hạn của Netflix kể từ khi bắt đầu chuyển dịch lên cloud AWS. Một số thất bại tiêu biểu mà hệ thống đã gặp phải bao gồm:
- Thất bại trong giải quyết các thành phần phụ thuộc trong dịch vụ;
- Thất bại trong việc thực thi các microservice (dẫn tới việc lỗi chồng lỗi – cascading failure);
- Thất bại trong việc kết nối tới một API do quá tải;
- Thất bại trong việc kết nối tới một instance hay server như OCA.
Để phát hiện và giải quyết các thất bại này, API Gateway Service Zuul đã được đưa ra. Nó có các tính năng có sẵn bên trong như trạng thái adaptive retry (giới hạn tỉ lệ yêu cầu từ AWS để tăng khả năng thành công trong lần thực thi tiếp theo), giới hạn các call đồng thời tới API ứng dụng. Ngược lại, API ứng dụng sử dụng các lệnh Hystrix để call time-out tới microservice, dừng các lỗi xếp tầng và cô lập các điểm thất bại khỏi các khu vực khác.
Đội ngũ kỹ thuật của Netflix nổi tiếng với hoạt động thực hành kỹ thuật hỗn loạn (chaos engineering). Ý tưởng là đưa ra các lỗi giả ngẫu nhiên vào môi trường production và xây dựng giải pháp để tự động phát hiện, cô lập và phục hồi từ các thất bại đó. Các lỗi có thể gia tăng thời gian phản hồi của một số microservices, ngừng dịch vụ hay làm ngưng server, instance, thậm chí “đánh sập” toàn bộ hạ tầng kiến trúc của một region. Bằng việc đưa ra các thất bại thực tiễn có thể xảy ra với sản phẩm, Netflix có thể khám phá ra các kẽ hở, điểm yếu nhanh chóng trước khi họ thực sự đối mặt với vấn đề đó trong thực tế.
7. Khả năng mở rộng (Scalability)
Trong phần này, ta sẽ phân tích khả năng mở rộng của dịch vụ streaming trên Netflix sử dụng mở rộng bề ngang, thực thi song song và phân vùng cơ sở dữ liệu. Các phần khác như caching (lưu vào bộ nhớ đệm) và cân bằng tải (load balancing) cũng phần nào giúp tăng khả năng mở rộng – điều đã được đề cập trong phần 4.
Đầu tiên, việc scaling ngang của instance EC2 trên Netflix được cung cấp bởi dịch vụ AWS Auto Scaling. Dịch vụ này tự động hóa việc khởi chạy các instance linh hoạt nếu cường độ của các yêu cầu tăng lên, đồng thời ngắt các instance không sử dụng tới. Cụ thể hơn, bỏ qua hàng ngàn lựa chọn về instance, Netflix đã phát triển Titus, một nền tảng quản lý container mã nguồn mở, giúp vận hành hơn 3 triệu container hằng tuần. Cùng với đó, mọi thành phần trong kiến trúc ở Hình số 2 đều có thể triển khai bên trong 1 container. Hơn thế, Titus cho phép container chạy đa miền (multi-regions) ở nhiều lục địa trên thế giới.
Thứ hai, việc triển khai 1 API ứng dụng hay 1 microservice ở phần 3.2.2. cũng giúp tăng cường khả năng mở rộng, bằng việc cho phép việc chạy song song nhiều tác vụ khác nhau trong Network Event Loop, và Outgoing Event Loop cho các hàm bất đồng bộ (async).
Cuối cùng, các cột lưu trữ dữ liệu rộng như Cassandra và các phần lưu trữ key-value object như ElasticSearch cũng cung cấp tính năng khả dụng và nâng cấp cao, và không có điểm thất bại duy nhất (single point of failure).
8. Kết luận
Nghiên cứu này đã mô tả toàn bộ kiến trúc cloud của dịch vụ streaming tại Netflix. Bài viết cũng phân tích các mục tiêu thiết kế khác nhau của hạ tầng như tính khả dụng, giảm độ trễ, khả năng mở rộng và tự phục hồi khỏi các thất bại trong network hay outages hệ thống. Tựu trung lại, kiến trúc cloud của Netflix, được chứng minh bởi hệ thống sản phẩm của họ tới tay hàng triệu người dùng, chạy trên hàng nghìn server ảo, đã cho ta thấy tính khả dụng cao, độ trễ tối ưu, khả năng mở rộng mạnh mẽ với việc kết nối với dịch vụ cloud AWS, và khả năng tự phục hồi với các thất bại trong network và outage hệ thống trên quy mô toàn cầu.
Phần lớn kiến trúc và các thành phần trong đó được học hỏi từ các nguồn tài nguyên online uy tín. Kể cả khi không có nhiều nguồn tư liệu trực tiếp mô tả việc lắp đặt microservice nội bộ, hay các công cụ và hệ thống dùng để quản lý các hoạt động của họ, nghiên cứu này vẫn có thể coi là một nguồn tham khảo quý giá, giúp ta hình dung được các một sản phẩm nổi tiếng đã được xây dựng [trên một kiến trúc cloud] ra sao.
Về VTI Cloud
VTI Cloud tự hào là Advanced Consulting Partner của AWS và Gold Partner của Microsoft nhằm đem đến sức mạnh của Điện toán đám mây và các dịch vụ CNTT hàng đầu đến với các tổ chức, doanh nghiệp tại thị trường Việt Nam và Nhật Bản. VTI Cloud sở hũu đội ngũ hơn 50+ kỹ sư về giải pháp được chứng nhận bởi AWS, cùng đội ngũ giàu kinh nghiệm với hàng trăm dự án lớn. Xây dựng các kiến trúc an toàn, hiệu suất cao, linh hoạt, và tối ưu chi phí cho khách hàng là nhiệm vụ hàng đầu của VTI Cloud trong sứ mệnh công nghệ hóa doanh nghiệp.
Liên hệ với chúng tôi: Tại đây
Nguồn: Cao Duc Nguyen từ medium.com