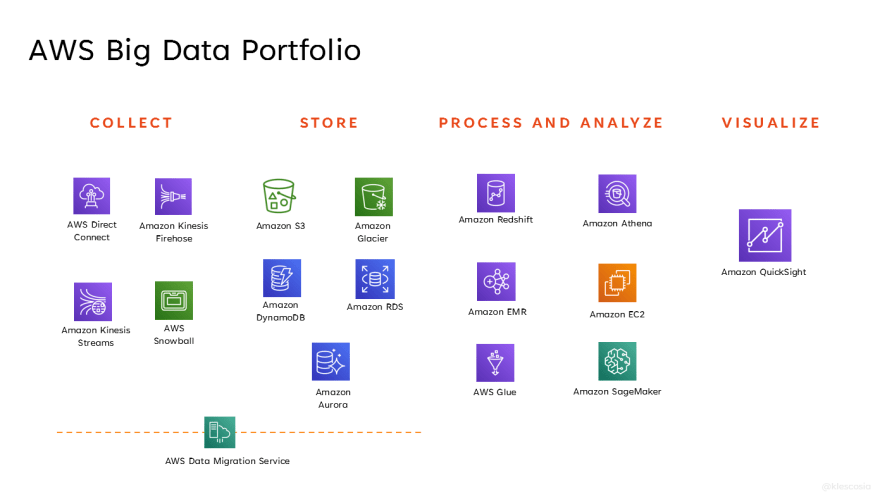
Bạn muốn xây dựng một data pipeline end-to-end với các dịch vụ của AWS?
Xin chúc mừng! Trong bài đăng này, VTI Cloud sẽ giới thiệu về danh mục Big Data của AWS.
Trước khi đi sâu vào bộ dịch vụ AWS cho Big Data, trước tiên chúng ta hãy xác định Big Data là gì.
Big Data là gì?
Theo Amazon Web Services (AWS):
Big Data có thể được mô tả là những thách thức về quản lý dữ liệu – do khối lượng, tốc độ hình thành và sự đa dạng của dữ liệu ngày càng tăng – không thể giải quyết được bằng cơ sở dữ liệu truyền thống.
Nói một cách đơn giản hơn:
Tập dữ liệu được coi là Big Data khi nó quá lớn hoặc phức tạp để được lưu trữ hoặc phân tích bởi các hệ thống dữ liệu truyền thống.
Khi xác định Big Data là gì, chúng ta sẽ tiếp tục với các dịch vụ AWS được sử dụng để giúp giải quyết những thách thức của Big Data.
Công đoạn 1: Thu thập
Việc thu thập dữ liệu thô (raw data) luôn là một thách thức đối với nhiều tổ chức, đặc biệt là đối với các nhà phát triển vì các doanh nghiệp luôn có các hệ thống nguồn phức tạp khác nhau nằm rải rác trong công ty như hệ thống ERP, hệ thống CRM, CSDL giao dịch, v.v.
Doanh nghiệp cũng phải suy nghĩ về cách họ sẽ tích hợp dữ liệu giữa các hệ thống này để tạo ra một cái nhìn thống nhất cho dữ liệu công ty.
AWS giúp doanh nghiệp thực hiện các bước này dễ dàng hơn, cho phép các nhà phát triển nhập dữ liệu (có cấu trúc và không có cấu trúc) theo thời gian thực một cách hàng loạt.
Các dịch vụ hỗ trợ công đoạn thu thập
AWS Direct Connect
AWS Direct Connect là một dịch vụ mạng cung cấp một giải pháp thay thế cho việc sử dụng internet để kết nối với AWS.
Sử dụng AWS Direct Connect, dữ liệu trước đây đã được truyền qua internet sẽ được phân phối thông qua kết nối mạng riêng giữa các cơ sở của người dùng và AWS.
Điều này hữu ích nếu người dùng muốn có hiệu suất mạng nhất quán hoặc nếu có khối lượng công việc nhiều băng thông.
Đọc thêm tại bài viết trước của VTI Cloud: AWS Direct Connect là gì? | VTI CLOUD
Amazon Kinesis
Dễ dàng thu thập, xử lý và phân tích các luồng video và dữ liệu trong thời gian thực.
Amazon Kinesis cho phép xử lý và phân tích dữ liệu khi dữ liệu đến và phản hồi ngay lập tức thay vì phải đợi cho đến khi tất cả dữ liệu được thu thập trước khi quá trình xử lý có thể bắt đầu.
Amazon Kinesis được quản lý hoàn toàn và chạy các ứng dụng phát trực tuyến của doanh nghiệp mà không yêu cầu quản lý bất kỳ cơ sở hạ tầng nào.
Kinesis có 4 chức năng:
-
Kinesis Video Streams: Ghi lại, xử lý và lưu trữ các luồng video
-
Kinesis Data Streams: Chụp, xử lý và lưu trữ các luồng dữ liệu
-
Kinesis Data Firehose: Tải luồng dữ liệu vào kho dữ liệu AWS
-
Kinesis Data Analytics: Phân tích luồng dữ liệu với SQL hoặc Apache Flink
Amazon Kinesis Video Streams
Kinesis Video Streams giúp dễ dàng truyền phát video một cách an toàn từ các thiết bị được kết nối tới AWS để phân tích, học máy (ML) và các quá trình xử lý khác.
Amazon Kinesis Data Streams
Kinesis Data Streams là một dịch vụ truyền dữ liệu thời gian thực có thể mở rộng và bền bỉ, có thể liên tục thu thập hàng gigabyte (GB) dữ liệu mỗi giây từ hàng trăm nghìn nguồn khác nhau.
Amazon Kinesis Data Firehose
Kinesis Data Analytics là cách dễ nhất để xử lý các luồng dữ liệu trong thời gian thực với SQL hoặc Apache Flink mà không cần phải học các ngôn ngữ lập trình hoặc framework mới.
Amazon Kinesis Data Analytics
Kinesis Data Analytics là cách dễ nhất để xử lý các luồng dữ liệu trong thời gian thực với SQL hoặc Apache Flink mà không cần phải học các ngôn ngữ lập trình hoặc framework mới.
AWS Snowball
Một cách khá thú vị để di chuyển dữ liệu của bạn từ hạ tầng on-premises lên AWS Cloud là AWS Snowball. Đây là dịch vụ cung cấp các thiết bị an toàn và đảm bảo, vì vậy bạn có thể mang khả năng lưu trữ và tính toán của AWS vào các môi trường biên, đồng thời truyền dữ liệu vào và ra AWS.
Amazon S3
Amazon S3 Glacier là dịch vụ lưu trữ chi phí cực thấp, cung cấp khả năng lưu trữ an toàn, bền bỉ và linh hoạt để sao lưu và lưu trữ dữ liệu.
Điều này đáp ứng hoàn hảo nhu cầu của các doanh nghiệp hoặc tổ chức cần lưu trữ dữ liệu của họ trong nhiều năm và thậm chí nhiều thập kỷ!
Công đoạn 2: Lưu trữ
Thực sự chúng tôi là người hâm mộ lớn của Amazon S3, do khả năng mở rộng và cách sử dụng dễ dàng của nó. Nếu như không sử dụng Amazon S3 cho các datalake của mình, thì có thể bạn đang bỏ lỡ rất nhiều thứ.
Rõ ràng là có rất nhiều yếu tố cần được xem xét khi xây dựng dự án Big Data. Bất kỳ nền tảng Big Data nào cũng cần một kho lưu trữ an toàn, linh hoạt và bền bỉ để lưu trữ dữ liệu trước hoặc thậm chí sau khi xử lý các tác vụ, AWS cung cấp các dịch vụ tùy thuộc vào yêu cầu cụ thể của khách hàng.
Các dịch vụ hỗ trợ công đoạn lưu trữ
Amazon DynamoDB
Amazon DynamoDB là cơ sở dữ liệu dạng tài liệu (document) mang lại hiệu suất lên tới một chữ số mili giây ở bất kỳ quy mô nào.
Đây là một trong những Dịch vụ AWS được quản lý hoàn toàn, có nghĩa là bạn không phải lo lắng về việc thiết lập cơ sở hạ tầng và cập nhật phần mềm mà chỉ cần sử dụng dịch vụ.
Đọc thêm: https://aws.amazon.com/dynamodb/
Amazon RDS
Amazon RDS là một dịch vụ được quản lý giúp dễ dàng thiết lập, vận hành và mở rộng quy mô cơ sở dữ liệu quan hệ trên đám mây.
Amazon RDS hỗ trợ công cụ cơ sở dữ liệu Amazon Aurora, MySQL, MariaDB, Oracle, SQL Server và PostgreSQL và thường là dịch vụ được sử dụng khi khách hàng migrate CSDL từ on-premises lên AWS.
Amazon Aurora
Amazon Aurora là một công cụ cơ sở dữ liệu quan hệ kết hợp tốc độ và độ tin cậy của cơ sở dữ liệu thương mại cao cấp với tính đơn giản và hiệu quả về chi phí của cơ sở dữ liệu mã nguồn mở.
Công đoạn 3: Xử lý và phân tích
Đây là bước mà dữ liệu được chuyển từ trạng thái thô của nó thành một định dạng có thể tiêu thụ – thường bằng cách sắp xếp, tổng hợp, nối và thậm chí thực hiện các chức năng và thuật toán nâng cao hơn.
Các tập dữ liệu kết quả sau đó được lưu trữ để xử lý thêm hoặc có sẵn để tiêu thụ thông qua các công cụ trực quan hóa dữ liệu và business intelligence.
Các dịch vụ hỗ trợ công đoạn xử lý và phân tích
Amazon Redshift
Amazon Redshift là kho dữ liệu đám mây được sử dụng rộng rãi nhất.
Nó giúp phân tích tất cả dữ liệu của bạn nhanh chóng, đơn giản và tiết kiệm chi phí bằng cách sử dụng SQL tiêu chuẩn và các công cụ Business Intelligence (BI) hiện có của bạn.
Nó cho phép bạn chạy các truy vấn phân tích phức tạp từ hàng terabyte (TB) đến hàng petabyte (PB, 1 PB dữ liệu có cấu trúc và bán cấu trúc, sử dụng tối ưu hóa truy vấn phức tạp, lưu trữ dạng cột trên bộ nhớ hiệu suất cao và thực thi truy vấn song song hàng loạt.
Amazon Athena
Amazon Athena là một dịch vụ truy vấn tương tác giúp dễ dàng phân tích dữ liệu trong Amazon S3 bằng cách sử dụng SQL tiêu chuẩn.
Dịch vụ Amazon Athena không có máy chủ, vì vậy không có cơ sở hạ tầng để quản lý và bạn chỉ trả tiền cho các truy vấn mà bạn chạy.
Chúng tôi đã sử dụng Athena rất nhiều trong việc triển khai của mình và tôi phải nói rằng chúng thực sự đã giúp chúng tôi về Khám phá dữ liệu và Xác thực dữ liệu.
AWS Glue
AWS Glue là dịch vụ tích hợp dữ liệu không cần máy chủ giúp dễ dàng khám phá, chuẩn bị và kết hợp dữ liệu để phân tích, học máy và phát triển ứng dụng.
AWS Glue đã phát triển đáng kể từ bản phát hành ban đầu 0.9 lên AWS Glue 2.0. Cùng với đó là những cải tiến giúp gắn kết tất cả các pipelines lại với nhau.
Amazon EMR
Amazon EMR là một dịch vụ web cho phép các doanh nghiệp, nhà nghiên cứu, nhà phân tích dữ liệu và nhà phát triển xử lý lượng lớn dữ liệu một cách dễ dàng và tiết kiệm chi phí.
Nó sử dụng khung Hadoop được lưu trữ chạy trên cơ sở hạ tầng quy mô web của Amazon Elastic Compute Cloud (Amazon EC2) và Amazon Simple Storage Service (Amazon S3).
Trái ngược với Glue, không có máy chủ có nghĩa là bạn không cần cung cấp máy chủ của riêng mình, EMR cho phép bạn linh hoạt hơn về khối lượng công việc tùy thuộc vào khối lượng công việc xử lý dữ liệu của bạn “lớn” như thế nào.
Amazon EC2
Amazon Elastic Compute Cloud (Amazon EC2) là một dịch vụ web cung cấp khả năng tính toán có thể thay đổi kích thước trên đám mây. Về cơ bản, máy ảo của bạn trên đám mây có rất nhiều trường hợp sử dụng, đúng với tên gọi của nó là “Elastic”.
Amazon Sagemaker
Amazon SageMaker là một dịch vụ được quản lý hoàn toàn cung cấp cho mọi nhà phát triển và nhà khoa học dữ liệu khả năng xây dựng, đào tạo và triển khai các mô hình học máy (ML) một cách nhanh chóng.
SageMaker loại bỏ những công việc nặng nhọc khỏi mỗi bước của quy trình máy học để giúp việc phát triển các mô hình chất lượng cao trở nên dễ dàng hơn.
AWS re: Invent 2020 cũng đã giới thiệu cho chúng tôi rất nhiều cải tiến đáng kể đối với Amazon Sagemaker như Data Wrangler, Clarify, SageMaker pipe, v.v.
Công đoạn 4: Hình dung
Dữ liệu lớn là tất cả về việc nhận được giá trị cao, thông tin chi tiết hữu ích từ nội dung dữ liệu của bạn.
Lý tưởng nhất là dữ liệu được cung cấp cho các bên liên quan thông qua các công cụ thông minh kinh doanh tự phục vụ và các công cụ trực quan hóa dữ liệu linh hoạt cho phép khám phá tập dữ liệu nhanh chóng và dễ dàng.
Tùy thuộc vào loại phân tích, người dùng cuối cũng có thể sử dụng dữ liệu kết quả dưới dạng “dự đoán” thống kê – trong trường hợp phân tích dự đoán – hoặc hành động được đề xuất – trong trường hợp phân tích mô tả.
Các dịch vụ hỗ trợ công đoạn hình dung
Amazon QuickSight
Amazon QuickSight là một dịch vụ Business Analytics được hỗ trợ bởi đám mây, rất nhanh, dễ sử dụng, giúp tất cả nhân viên trong tổ chức dễ dàng trực quan hóa, thực hiện phân tích đặc biệt và nhanh chóng nhận được thông tin chi tiết về doanh nghiệp từ dữ liệu của họ, bất cứ lúc nào, trên bất cứ thiết bị nào.
QuickSight rất dễ sử dụng và cũng đã thực hiện một số cải tiến lớn kể từ khi được phát hành công khai. Tuy còn khá mới so với các công cụ BI lớn khác nhưng Amazon QuickSight rất có tiềm năng, đặc biệt khi nó là một giải pháp BI tiết kiệm chi phí.
Về VTI Cloud
VTI Cloud là Đối tác cấp cao (Advanced Consulting Partner) của AWS, với đội ngũ hơn 50+ kỹ sư về giải pháp được chứng nhận bởi AWS. Với mong muốn hỗ trợ khách hàng trong hành trình chuyển đổi số và dịch chuyển lên đám mây AWS, VTI Cloud tự hào là đơn vị tiên phong trong việc tư vấn giải pháp, phát triển phần mềm và triển khai hạ tầng AWS cho khách hàng tại Việt Nam và Nhật Bản.
Xây dựng các kiến trúc an toàn, hiệu suất cao, linh hoạt, và tối ưu chi phí cho khách hàng là nhiệm vụ hàng đầu của VTI Cloud trong sứ mệnh công nghệ hóa doanh nghiệp.
References:
https://aws.amazon.com/directconnect/
https://aws.amazon.com/kinesis/
https://aws.amazon.com/snowball/
https://aws.amazon.com/glacier/
https://aws.amazon.com/dynamodb/
https://aws.amazon.com/redshift/
https://aws.amazon.com/athena/
https://aws.amazon.com/sagemaker/
https://aws.amazon.com/quicksight/