Data is a precious resource for any modern business.
The information a company collects about its customers, its operations, its products, and services is vital not only to its efficient day-to-day running but its survival.
Being able to properly store, secure, and retrieve data effectively can make all the difference in providing exceptional customer experiences, optimizing processes, and making informed, proactive decisions.
Given that data and its proper handling are so important, choosing the right way to manage it is a big decision. There are more database options available to cloud customers than ever before, and no cloud service provider offers more choice than AWS.
Having your pick of so many databases makes it easier to find one that fits your business requirements without compromise—provided you know the benefits and drawbacks of each option.
Let’s take a look at the databases available on AWS, so you can find the right one to suit all your data needs.
- Amazon Aurora
- Amazon Redshift
- Amazon DynamoDB
- Amazon ElastiCache
- Amazon Neptune
- Amazon DocumentDB
- Amazon TimeStream
- Amazon Quantum Ledger Database
Databases on AWS
Currently, AWS offers 14 different database engines on its platform, with each one purpose-built and applicable to a range of use cases. By providing so many options, AWS aims to help businesses move away from a monolithic, one-size-fits-all approach and choose the right database for the job, even if that means operating several concurrently.
So, why use an AWS database? “My response would be ‘Why wouldn’t you use a cloud database?’” says Marc Weaver, Founder at databasable.
“It takes care of setup, availability, backups and recovery, hardware, management overhead, and licensing AND also provides simplified update processes. It’s a win-win-win-win situation.”
“Aside from taking care of most of the management tasks, flexibility is the main reason,” says Marc. “You can easily try different database platforms (SQL Server, MySQL, MariaDB, etc.) and different database types (SQL, NoSQL, data warehouse, time series, etc.) without having to commit to hardware, licensing, or resources. You only pay for what you use and can break away at any time with no long-term commitments.”
Ido Neeman, CEO at serverless platform developer Nuweba, agrees that there are a number of super attractive reasons to warehouse data in the cloud.
Firstly, they’re distributed and disaster-safe, utilizing multi-region replication and encryption to protect against both data loss and security threats. AWS databases are self-monitoring, self-healing, and scale automatically, so you can be sure that you’re getting maximum up-time on your workloads.
“They’re also cost-effective: this depends on the service, of course, but most cloud databases use a pay-as-you-go model, so you pay only for the usage and needs of a business,” says Ido.
“They’re scalable too, so you can easily increase your I/O operations or storage capacity. Security is managed by the provider, who usually maintains the service with security patches and software updates so the business shouldn’t have to. All of these things allow a business to save money and time with worry-free service.”
Choosing the right AWS database
When narrowing down the right database for the job, Ido suggests businesses should consider what kind of usability it needs from the service, and choose a service according to its functionality.
“An organization should also consider how scalable the service should be,” he says, “and therefore decide whether the price model fits its cost strategy. Lastly, but sometimes most importantly, performance and speed must be considered. Low performance can result in poor user-experience, high costs, and can damage the entire architecture.”
With more than a dozen database engines designed for a range of purposes on offer, you can be sure you’re getting high performance no matter which engine you opt for. What’s really important, says Ido, is the functionality: “It’s all about the business need—whether the priority is a fast query, a fast store, or even high reliability and the schema of the data.”
“For example, if a business likes to store rich data schema—such as different tables with connections between them—then Amazon RDS may be the preferred option. For storing key-value documents, especially for web apps, where you don’t have to declare the model in advance, DynamoDB could work (it’s also highly scalable). If in-memory data store—less reliable but really quick—with an ultra-fast query is needed, ElastiCache would be a good choice.”
Given the broad spectrum of innovative database solutions available on AWS, Marc’s advice is to avoid sticking to what you know.
“Don’t fall into the same old routine,” he warns. “Just because your business has used Oracle or SQL Server for years doesn’t mean that you should persist with the same thought process.
“Databases are not as complicated as they once were, so look at what fits best for each part of your application. The open-source platforms are just as good as the expensive legacy platforms; it may be that a mix of open-source SQL and NoSQL works better than sticking to the norm and forcing square pegs in round holes.”
Database types
Amazon’s database stable includes various types of data warehouses. Here’s a quick glossary to explain the differences between these popular database categories:
- Relational databases store data in tables with columns and rows, with each row representing a single record, differentiated with a unique ID known as a key, and each column containing data related to that record. Relational databases have been around since the 1970s and are now the most commonly used type of data warehouse. Many relational databases are managed using the programming language SQL.
- Key-value databases are non-relational databases that use a basic key-value method to store data. Data is warehoused in key-value pairs; each key serves as a unique identifier for a single value within the collection. This works in a similar way to a dictionary: the word is the key, and the definition is the value.
- In-memory databases are non-relational databases that rely on memory for data storage, making queries faster by eliminating the need to access disks.
- Document databases offer flexible, semi-structured, hierarchical storage for use cases like catalogs and user profiles, and content management systems such as blogs and video platforms.
- Graph databases store data not in tables, but in an interconnected web-like structure that allows complex relationships between data to be mapped and queried.
- Time-series databases are designed to store and retrieve data points that are associated with timestamps.
- Ledger databases contain both tables of data and an immutable journal that logs all changes to data, creating a blockchain record of all updates.
Amazon Aurora
Database type: Relational
Best for SaaS apps like ERP, CRM, and eCommerce
Amazon Aurora is a MySQL relational database engine known for its speed and simplicity.
Typically up to five times faster than standard MySQL databases, it’s also compatible with PostgreSQL, and is up to three times quicker than standard PostgreSQL options.
Secure and durable, Aurora databases are fully managed by AWS’s Relational Database Service (RDS), meaning all administrative work is taken care of at the vendor’s end. Aurora stores data in 10GB “chunks”; and if you need to increase the size of your Aurora database, it automatically scales up in 10GB increments, up to a maximum capacity of 64TB.
Aurora databases are created within an Amazon Virtual Private Cloud (VPC), so users can quarantine a database for use solely within their network for extra security if necessary. Plus, all network keys are user-assigned and can be managed with the AWS Key Management Service.
Data stored in an Aurora database is replicated six times across three Availability Zones (AZs) to make sure your data is always available when you need it.
If any corruption occurs, the database self-heals by pulling the copied data back into the main database. Data is continuously backed up to Amazon’s S3 storage platform.
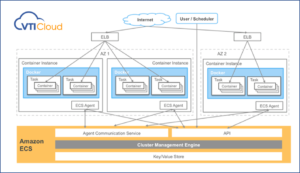
What is Amazon RDS?
Not a database engine itself, Amazon Relational Database Service (RDS) is a web service tool created to help users set up, run, and scale relational databases in the cloud.
Amazon RDS is the service that manages the administrative tasks that come with operating a relational database like auto-scaling, monitoring, software patching, and managing backups and recovery.Amazon RDS can be used to manage six different database engines.
As well as Amazon Aurora, it can be used with Postage SQL, MySQL, MariaDB, Oracle, and Microsoft SQLServer. That means you get all the benefits of Amazon RDS while still being able to stick with database engines you’re already familiar with—kind of like hiring a butler to work in a house you already own.
Amazon Redshift
Database type: Relational
Best for Large-scale data warehouses and data migrations, analytics
Amazon Redshift is the most popular AWS database, hosting more than 15,000 active customers. Businesses using Redshift include Lyft, Mcdonald’s, and Philips, but that’s not to say it’s only suited to enterprise businesses; its high performance and scalability mean it’s a good choice for any kind of business with mission-critical analytical workloads.
A petabyte-scale data warehouse, Redshift was designed primarily to offer high-performance data storage that enables users to access their data in real-time and feed data into business intelligence and analytical tools.
Redshift’s popularity is partially down to its speed—it’s the fastest data warehouse on the market today. Its high performance is driven by two key factors: its columnar data storage method, and its Massively Parallel Processing (MPP) design, which distributes workload equally across multiple nodes for speedy processing of even the most complex queries.
What else makes Redshift such a giant in the database world? “Redshift is meant to deal with huge amounts of data,” proposes Ido. “It offers exceptional performance, alongside horizontal scale, and an attractive price point: those factors are among what makes it the most popular service.”
Although Redshift is a great product, Amazon APN offering Snowflake Data Warehouse is a challenger that’s gaining a lot of traction and interest. Organizations should definitely check out and compare Snowflake and Redshift before deciding which solution to use.
Each Amazon Redshift data warehouse is made up of a collection of computing resources known as nodes. These groups of nodes as called clusters.
Nodes are available in different sizes, depending on the total storage capacity you need, and the complexity of your queries. Redshift can be scaled up or down with just a few clicks if you need to add more nodes.
All other admin factors, like data backups, upgrades, and patches, are taken care of at AWS’s end.
Amazon DynamoDB
Database type: Key-value
Best for Mobile and web apps, gaming, IoT
Amazon DynamoDB is a fully managed, NoSQL database that’s highly consistent and scalable. A key-value and document platform, DynamoDB is multi-region, multi-master, has built-in security, and backup and restore features.
With DynamoDB, users create database tables that can store and retrieve huge amounts of data; it then automatically distributes data and traffic across multiple servers to ensure maximum throughput.
It’s an extremely powerful platform for querying data, able to handle more than 10 trillion requests per day, at peaks of more than 20 million requests per second.
Amazon ElastiCache
Database type: In-memory
Best for: Caching, chat, BI and analytics, session store, gaming leaderboards
Amazon ElastiCache provides in-memory data storage and cache for apps and websites. It simplifies the management and monitoring of in-memory environments, helping your business to cut load times and create better-performing services for users.
ElastiCache offers a platform for the speedy retrieval of information-managed, in-memory systems, eliminating the need to rely on disk-based databases. Like AWS’s other database services, ElastiCache is fully managed, removing the burden of patching, provisioning, and recovery for users.
For data that’s accessed often, ElastiCache offers an alternative to slower, more expensive data retrieval.
Looking for top AWS to run your databases?
Take a look at our bank of pre-screened AWS professionals and take the first step toward landing the best administrators, developers, and consultants in the market.
Amazon Neptune
Database type: Graph
Best for Fraud detection, social networking, knowledge graphs, recommendation engines
Amazon Neptune is a graph database service, purpose-built and optimized to provide storage of billions of relationships and enable super-fast querying.
Amazon Neptune’s graph engine is great for social networking, recommendation engines, and fraud detection: all use cases that benefit from a database that can map complex relationships between bits of data, and that can be queried faster than those spread across multiple tables in a traditional RDB.
Neptune makes it straightforward for businesses to take advantage of highly connected datasets, and supports popular graph query languages to pull relationship data with millisecond latency. Like Aurora, Neptune duplicates data six times across three AZs, in 10 GB segments.
Amazon DocumentDB
Database type: Document
Best for Content management, catalogs, user profiles
Amazon DocumentDB is a fast, fully managed document database service: a non-relational database built to store and query data as documents.
One of its big draws is that it’s compatible with MongoDB workloads. Developers can use the same app code, drivers, and tools to run and manage workloads on DocumentDB, enjoying all of the improved performance and scalability that comes with it without having to deal with MongoDB infrastructure.
Amazon DocumentDB offers twice the throughput of MongoDB managed services, and splits up compute and storage so both aspects can scale independently to meet individual needs.
DocumentDB comes with all the bells and whistles you’d expect from an AWS database; high availability, durability, security, and auto-scaling.
Amazon Timestream
Database type: Time-series
Best for IoT applications, DevOps, industrial telemetry
A time-series database for IoT and operational apps, Amazon Timestream can store and process trillions of events every day.
Developed to provide optimized database services for the growing number of IoT devices and smart machines entering the market, Timestream specializes in time-series data—data that measures how things change over time.
Timestream aims to overcome the limitations of RDBs in analyzing time-series data, given that traditional RDBs lack the capacity to store and retrieve data by time intervals.
It also makes it easy to store and analyze log data for DevOps, sensor data for IoT applications, and industrial telemetry data for equipment maintenance purposes.
It comes with built-in analytical functions too, like smoothing, approximation, and interpolation. Timestream’s adaptive query processing engine means the databases get smarter over time, making analysis of your data even faster. It also self-manages rollups, retention, tiering, and data compression to make sure you’re only using the capacity you need.
Amazon Quantum Ledger Database
Database type: Ledger
Best for Systems of record, financial transactions, supply chain data
The newest edition to Amazon’s database stable, Amazon Quantum Ledger Database is a centralized blockchain service, providing users with an absolute, cryptographically verifiable log.
Amazon QLDB creates permanent, unchangeable records of transactions, and can be used to store data for apps that require centralized, trusted authority.
The service preserves a complete, fixed history of the data within it: a history that can’t be amended or deleted after the fact. This makes it ideal for tracking financial information, e-commerce transactions, HR and payroll information, and logistics and manufacturing data.
The QLDB ledger is made up of tables. Each table has its own journal to track any and all changes made to the documents and data stored within the tables. These journals cannot be amended, and are indexed for fast querying.