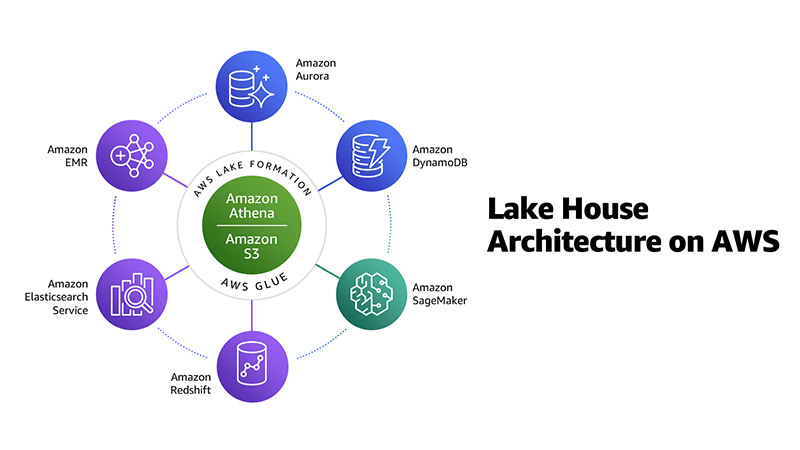
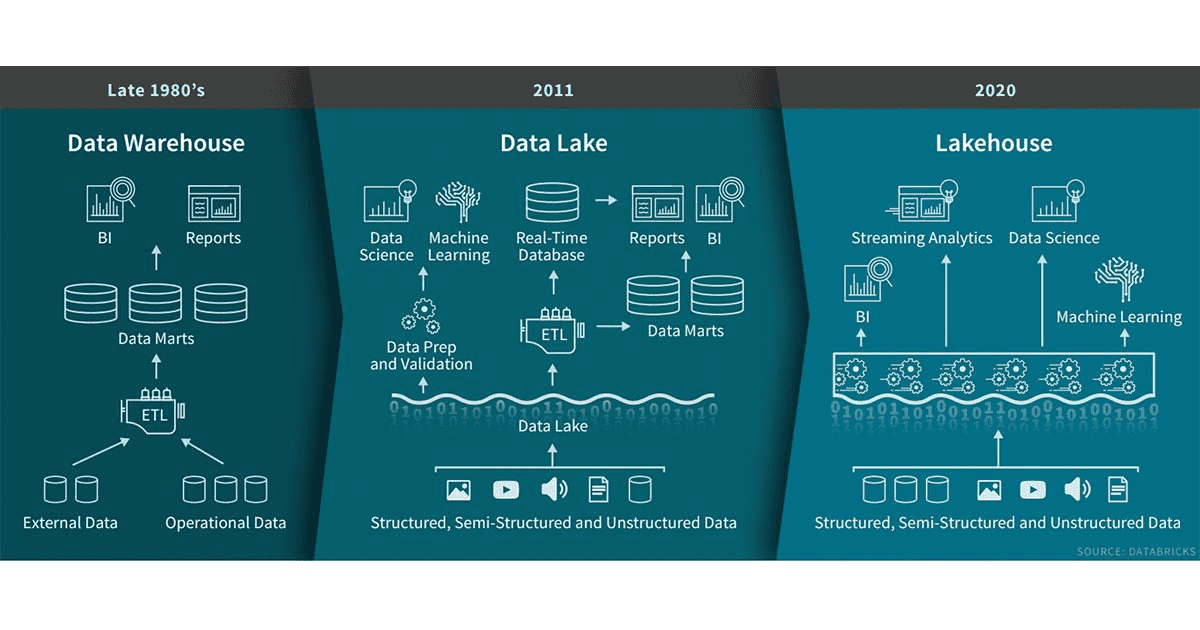
To get the best insights from all data, organizations need to move data between data lakes and data warehouses easily. As the data in these systems continues to grow, it becomes more difficult to migrate all of the data. To overcome the volume and migration problem to get the most out of all the data, the Lakehouse on AWS approach was introduced.
Businesses can fully own deeper and richer insights if they leverage and analyze all the data from their sources. However, this amount of data is huge and not arranged in any structure.
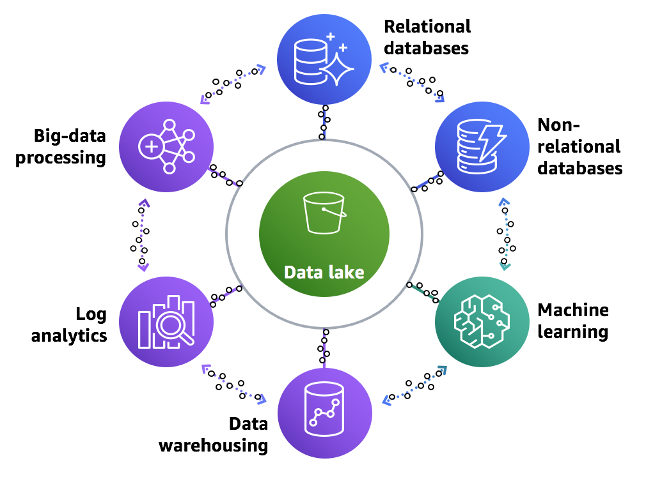
To analyze this amount of data, businesses must gather all their data from different silos and aggregate it all in one location, called a data lake, to perform analytics and machine learning (ML) directly on it. In addition, businesses also use a data warehouse service to get quick results for complex queries about structured data or search service to quickly search and analyze log data to monitor the health of the production system.
How to approach Lakehouse
As a modern data architecture, the Lakehouse approach is not only about integrating but also connecting the data lake, data warehouse, and all other purpose-built services into a unified whole.
Data lakes are the only place where you can run analytics on most of your data while analytics services are built to provide the speed you need for specific use cases like real-time dashboards and log analytics.
This Lakehouse approach includes the following key elements:
• Scalable Data Lake
• Purpose-built data services
• Seamless data movements
• Unified Governance
• Performant and Cost-effective
The following diagram illustrates this Lakehouse approach to real-world customer data and the necessary data migration between all data analytics services and the data warehouse, inside-out, outside-in, and around the perimeter:
The layered and componentized data analytics architecture allows businesses to use the right tools for the right job and provides the ability to quickly build architectures step-by-step.
You get the flexibility to evolve Lakehouse to meet current and future needs as you add new data sources, discover new use cases and develop newer analytical methods.
For this Lakehouse Architecture, you can organize it as a logical five-layer model, where each layer consists of many purpose-built components that address specific requirements.
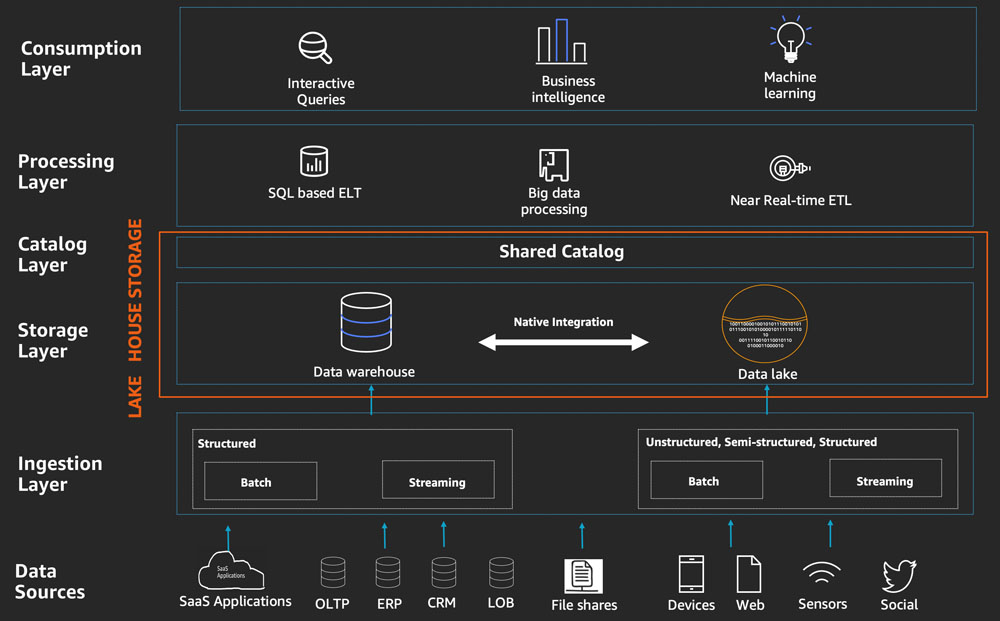
Before diving into the 5 layers, let’s talk about the supplies for Lakehouse Architecture.
1. Data Sources
The Lakehouse architecture allows you to ingest and analyze data from a variety of sources. Many of these sources such as line of business (LOB) applications, ERP applications, and CRM applications generate batches of highly structured data at fixed intervals.
In addition to internal sources, you can get data from modern sources like web apps, mobile devices, sensors, video streams, and social media. These modern sources typically produce semi-structured and unstructured data, often in continuous streams.
2. Data Ingestion Layer
The Ingestion layer in Lakehouse Architecture is responsible for importing data into the Lakehouse storage layer. It provides connectivity to internal and external data sources over a variety of protocols. It can ingest and feed real-time and batch streaming data into the data warehouse as well as the data lake components of the Lakehouse storage layer.
3. Data Storage Layer
The data storage layer is responsible for providing durable, scalable, and highly cost-effective components for storing and managing large amounts of data. In the Lakehouse Architecture, the data warehouse and data lake are natively integrated to provide a cost-effective integrated storage layer that supports unstructured data as well as highly structured and modeled data. The storage layer can store data in different states of availability, including raw, trusted-conformed, enriched, and modeled.
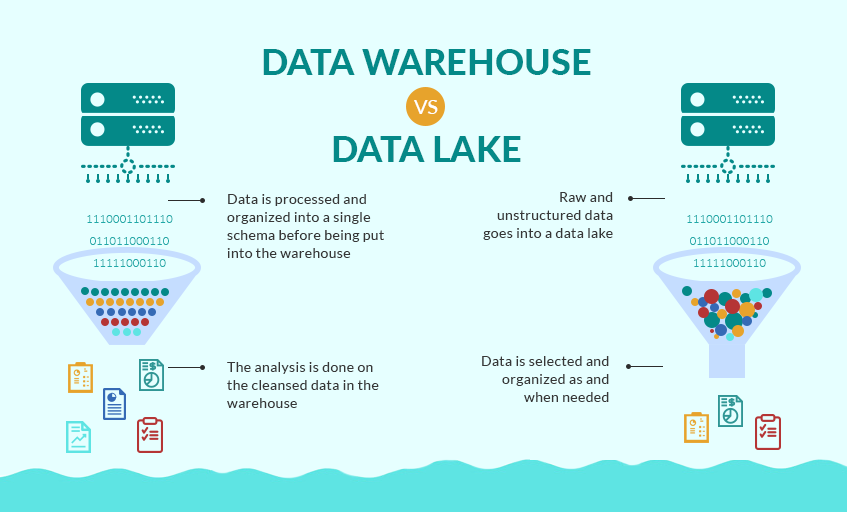
3.1. Structured data storage in a data warehouse
A data warehouse stores highly reliable, consistent data structured into a star, snowflake, data vault, or highly denormalized schemas. Data stored in a warehouse is typically obtained from highly structured internal and external sources such as transactional systems, relational databases, and other structured operational sources, often in a regular rhythm.
Modern cloud-native data warehouses can often store petabyte-scale data in built-in high-performance storage in a compressed, columnar format. Through MPP tools and fast attached storage, a modern cloud-native data warehouse provides low-latency turnaround for complex SQL queries.
To provide ordered, highly compliant, and reliable data, before storing the data in a warehouse, you need to pass the source data through a significant amount of preprocessing, validation, and transformation using extract, transform, load (ETL) or extract, load, transform pipelines (ELT). All changes to data warehouse and schema data are strictly managed and validated to provide reliable datasets across business domains.
3.2. Structured and unstructured data storage in a Lakehouse Architecture
A data warehouse stores highly reliable, consistent data structured into a star, snowflake, data vault, or highly denormalized schemas. Data stored in a warehouse is typically obtained from highly structured internal and external sources such as transactional systems, relational databases, and other structured operational sources, often in a regular rhythm.
Modern cloud-native data warehouses can often store petabyte-scale data in built-in high-performance storage in a compressed, columnar format. Through MPP tools and fast attached storage, a modern cloud-native data warehouse provides low-latency turnaround for complex SQL queries.
To provide ordered, highly compliant, and reliable data, before storing the data in a warehouse, you need to pass the source data through a significant amount of preprocessing, validation, and transformation using extract, transform, load (ETL) or extract, load, transform pipelines (ELT). All changes to data warehouse and schema data are strictly managed and validated to provide reliable datasets across business domains.
4. Catalog Layer
The catalog layer is responsible for storing business and technical metadata about data sets stored in the Lakehouse storage layer. In the Lakehouse Architecture, the catalog is shared by both the data lake and the data warehouse and allows writing queries that combine data stored in the data lake as well as the data warehouse in the same SQL.
It allows you to track schema versions and detailed partitioning information of data sets. As the number of datasets increases, this layer provides search capabilities that help uncover data sets in the Lakehouse.
5. Lakehouse Interface
In the Lakehouse Architecture, the data warehouse and data lake are integrated natively at the storage layers as well as the common catalog layers to provide a unified Lakehouse interface for the processing and consuming layers.
The components of the Lakehouse processing and consuming layer can then use all the data stored in the Lakehouse storage layer (stored in both the data warehouse and the data lake) through a unified Lakehouse interface. unique like SQL or Spark.
You do not need to move data between the data warehouse and the data lake in either direction to allow access to all data in Lakehouse storage.
Native integration between the data warehouse and the data lake gives you the flexibility to do the following:
- Store exabytes of structured and unstructured data in highly cost-effective data lake storage as managed, modeled, and highly relevant structured data in hot data warehouse storage
- Leverage a single processing framework like Spark that can combine and analyze all data in a single path, whether it’s unstructured data in a data lake or structured data in a data warehouse
- Build SQL-based data warehouse native ETL or ELT pipelines that can combine flat relational data in the warehouse with complex, hierarchical data in the data lake
6. Data Processing Layer
Components in the data processing layer of the Lakehouse Architecture are responsible for transforming data into a consumable state through validation, cleaning, normalization, transformation, and data enrichment. The processing layer provides purpose-built components to perform many types of transformations, including data warehouse-style SQL, big data processing, and near-real-time ETL.
The processing layer provides the fastest time to market by providing purpose-built components that match the right data set characteristics (size, format, schema, speed), processing tasks at hand, and available skill sets (SQL, Spark).
The processing layer is cost-effectively scalable to handle large volumes of data and provides components to support schema-on-write, schema-on-read, partitioned datasets, and definitions. variety of data. The processing layer can access Lakehouse’s unified storage interfaces and the common catalog, thus accessing all data and metadata in Lakehouse. This has the following benefits:
- Avoid data redundancy, unnecessary data migration, and ETL code duplication that can occur when handling a data lake and data warehouse separately
- Reduce time to market
7. Data Consumption Layer
The Data Consumption Layer of the Lakehouse Architecture is responsible for providing scalable and performance components that use a unified Lakehouse interface to access all stored data. stored in the Lakehouse storage, and all metadata stored in the Lakehouse catalog.
It provides components built to enable analytics, including interactive SQL queries, warehouse-style analytics, BI and ML dashboards, enabling analytics democratization and assurance accessible to all individuals in an organization.
Elements in the consumption layer support the following:
- Query writing as well as for analytics and ML that access and combine data from traditional data warehouse dimensional schemas as well as tables stored in the data lake (requires schema-on-read)
- Process data sets stored in data lakes stored using a variety of open file formats such as Avro, Parquet, or ORC
- Optimize performance and cost through partition truncation when reading large, partitioned data sets stored in the data lake
To be continued
Just the first approach to the Lakehouse architecture, to continue the series in this topic, in the next sections we’ll dive into a reference architecture that uses AWS services to create each layer described in the Lakehouse logic architecture. Read more here.
About VTI Cloud
VTI Cloud is an Advanced Consulting Partner of AWS Vietnam with a team of over 50+ AWS certified solution engineers. With the desire to support customers in the journey of digital transformation and migration to the AWS cloud, VTI Cloud is proud to be a pioneer in consulting solutions, developing software, and deploying AWS infrastructure to customers in Vietnam and Japan.
Building safe, high-performance, flexible, and cost-effective architectures for customers is VTI Cloud’s leading mission in enterprise technology mission.